Satellite Data and Processing
Overview
The third significant CSIRO innovation for the eReefs remote sensing work package is the integration of the regional algorithms with the full time series satellite imagery in a high performance computing environment. The objective is to take the research algorithms “out of the lab” and make the production of comprehensive data sets routine. Creation of such a system, where CSIRO can efficiently support experiments that involve reprocessing of the whole archive, as well as daily generation of new data, is a key step towards delivery of a system that the Bureau can deploy in full production.
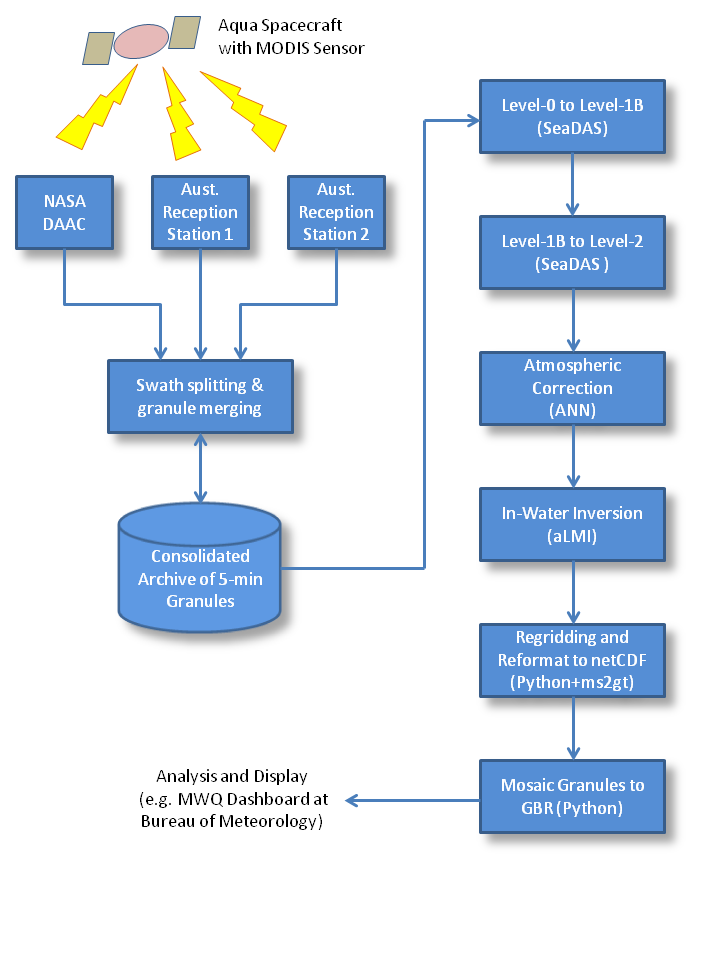
MODIS data processing workflow
The data processing workflow consists of several steps:
- assembling the data
- calibration and geolocation
- generation of ancillary fields
- atmospheric correction (ANN)
- in-water inversion (aLMI)
- regridding
- mosaicing
- distribution and access
The flowchart (right) illustrates the original system built in the first stage of eReefs (2012-2013) for processing data from the MODIS sensor. The most recent work has upgraded this system significantly. This includes adding the capability to process data from the VIIRS sensor, and also: recoding the regional algorithms to better take advantage of the high performance computing platform; reducing duplication and improving maintainability of the software codes; improving data and process versioning; and making it easier to support both the Bureau and CSIRO data production from within a common system.
VIIRS versus MODIS
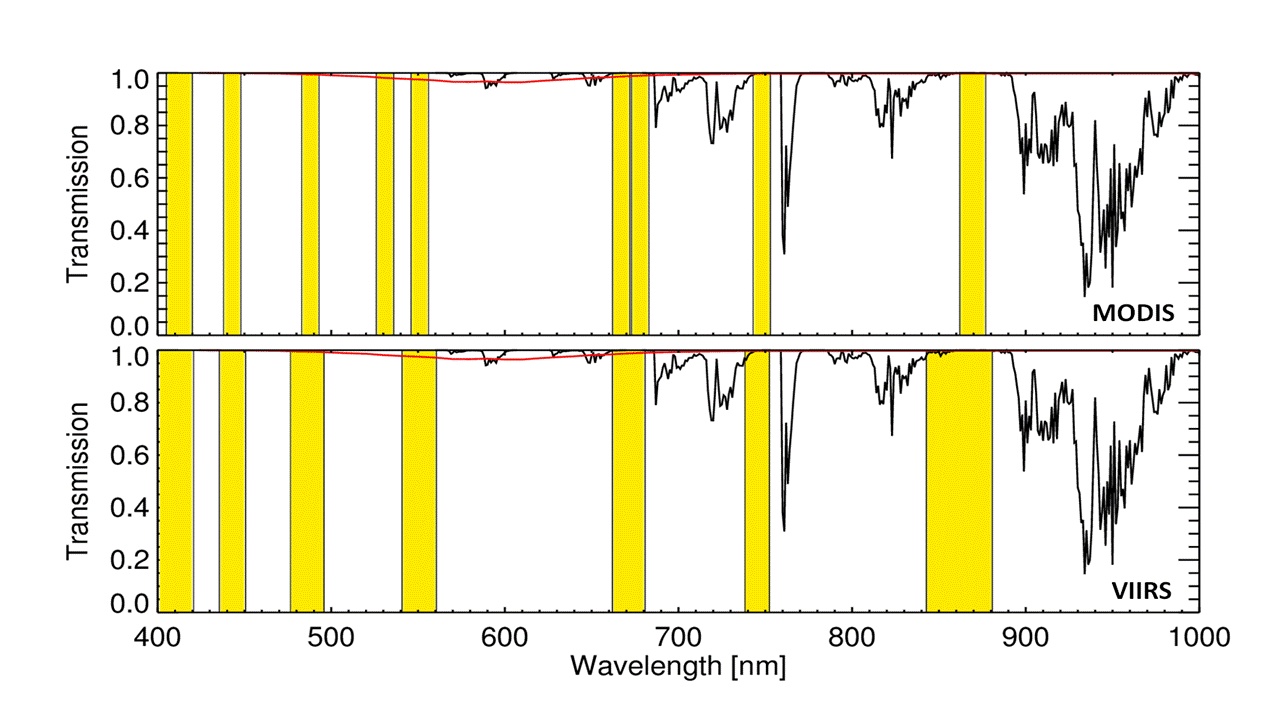
Spectral band characteristics of MODIS (top) and VIIRS (bottom) overlayed with the atmospheric transmission (black curve) and broad-band absorption of ozone (red curve) at 344 Dobson Units.
The first VIIRS (Visible and Infrared Imaging Radiometer Suite) sensor was launched on the Suomi/NPP spacecraft in November 2011 and was deployed in an orbit very close to that of Aqua, the satellite carrying MODIS. From an ocean colour perspective, the main difference compared to MODIS is a reduction in the number of spectral bands available for optical water quality assessment from nine to seven (left). Another key difference is that while the VIIRS scanner design is similar to MODIS, redundant pixels caused by overlap at the edge of the swath are deleted from the VIIRS data stream whereas they are retained by MODIS. This means a different approach is needed for the regridding step, which transforms the satellite image onto a map projection. A useful introduction to VIIRS and and a comparison with MODIS can be found on the web in Seaman (2013) and Guenther et al (2011) respectively.
For VIIRS the base processing software chain, which formats the raw data packets, calibrates and geolocates the data, is not yet as mature as for MODIS. This means that it is not yet possible to downlink VIIRS data direct from the Suomi/NPP spacecraft and process it right through to ocean colour products is the same manner as for MODIS. This results in a requirement in the extended processing workflow to bring partially processed VIIRS data in from the US via the Internet. In th flowchart above, this replaces everything up to, and including, the first step on the right hand side, so VIIRS data enters the system just before the “Level-1B to Level-2” processing step. This does not materially affect the timeliness of the eReefs ocean colour products from VIIRS, but it does however mean that a calibration revision applied in the US will necessitate a complete re-download of the archive to date.
New Implementations of Regional Algorithms
In the first phase of eReefs, the research algorithms (ANN an aLMI) were not recoded at all. Both were simply encapsulated within wrapper scripts that set up their inputs and outputs and managed the processing in the context of the workflow. Both algorithms were originally coded in the proprietary IDL language. The licencing requirements of IDL made it prohibitive to properly exploit the parallel processing capability of the National Computational Infrastructure. Consequently it was decided in the phase 2 work program to recode both algorithms in the open source Python language.
For the ANN, which uses C language routines to implement the neural network, this meant replacing the IDL code that managed the inputs and outputs and bad-data flagging with Python, and using the Cython package to call the C routines directly from Python. For the aLMI code over 3000 lines of IDL were translated to Python. In fact there was substantial redesign and refactoring involved as the aLMI codes had grown throughout the preceeding decade of research to meet a variety of experimental needs. To manage the large range of options for controlling the aLMI, a generic configuration file format was developed, and templates provided for for the standard use-cases of routine MODIS and VIIRS processing. The configuration file for each run is written to the output data file as a record of the specific choices made by the user for that run.
A secondary advantage of recoding both algorithms in Python, was the opportunity to simplify the impact of data file format changes on the algorithm implementations. The NASA SeaDAS package historically produced a variant of the Hierarchical Data Format (HDF) by default. Recently it has begun to support the network Common Data Form (netCDF) with the intention to make that the default supported format in the future. The original ANN and aLMI implementations only worked with the HDF format. In the course of the recoding of the algorithms to Python, all data file input and output was confined to a single Python module which could handle both formats, but presented a generic interface to the algorithms themselves. As a result, the new algorithms work with both formats, and should additional formats be required in future, only the one module will need changing, not the whole of the codes.
Better Data and Process Versioning
The transfer of the eReefs processing workflow has made it routine to process long time series of satellite data. As this processing become more frequent, it became apparent that substantially better recording of the processing choices was required in order to be able to distinguish different versions of the time series. The approach adopted was to carry a list of metadata in a structured text format (JSON) along with each data file in the workflow. Each module or processing step could easily update this file relevant to that step, and then at the very end, when data were finalised or exported, the metadata can easily be embedded in the data file as a metadata attribute. This approach is highly extensible, and means that the metadata management system is simplified because it doesn’t need to work with HDF or netCDF format data files. The metadata is explicitly tied to individual data files, not whole time series, so operational changes part way through a time series are captured naturally, and the metadata files can also be used to easily and quickly search for particular features, including time and location of individual scenes.
Improving Transfer To and Code Sharing with the Bureau
The last major change to the workflow codes undertaken in the phase 2 work was to improve the alignment of the codes used by CSIRO and the Bureau. For CSIRO the focus has been on long time series processed at the NCI. The approach has generally been to take the entire time series through a single processing step at time, allowing it to be checked and validated, and for the output of each stage to be used as a starting point for one or more versions of subsequent steps. In contrast the typical mode of operation for the Bureau, which has a focus on near real time data production, is to take a single scene and carry it right through each processing step as one computing task. These differences led in phase 1 to substantially different deployments of the workflows between the two partners.
In close consultation with Bureau staff, CSIRO has reorganised its workflow software to be able to operated naturally in both modes. This involved improving modularisation of each processing step, and providing a mechanism to run only a subset of steps, or the whole processing suite from within the same framework. Testing by CSIRO at the NCI indicates that this innovation will be a success, leading to a reduction in duplication and improvements to code maintenance, once the system is deployed by the Bureau in the first half of 2016.