AutoMap Datasets and Code
Data61/2D3D Dataset (formerly known as NICTA/2D3D)
The Data61/2D3D Dataset is made freely available to the scientific community. Any publications resulting from the use of this dataset, and derivative forms, should cite the following paper:
S. Taghavi Namin, M. Najafi, M. Salzmann and L. Petersson, A Multi-Modal Graphical Model for Scene Analysis, WACV, 2015.
Data61/2D3D dataset has been prepared for outdoor scene understanding which consists of a series of 2D panoramic images with corresponding 3D LIDAR point clouds. It contains 10 outdoor scenes, each of which includes a block of 3D point cloud together with several panoramic images. The number of 3D points in the scenes varies from 1 to 2 millions, and each scene contains between 11 and 21 panoramic images.
The dataset was manually annotated in the 3D domain and the ground truth labeling of the panoramic images were obtained via 3D-2D projection of the 3D labels. The 2D ground truth images were later checked and retouched to produce a more precise 2D ground truth. This step accounts for projection errors due to misalignments or parallax and also deals with moving and/or reflective objects whose point cloud data is very sparse. Additionally, the label Sky, which does not exist in the 3D data, was included as a new label in the 2D images. The point cloud data is seen from multiple viewpoints thanks to the 360 degree panoramic images, and its FOV covers the entire image (both vertically and horizontally) instead of just a portion in other datasets.
The second advantage of the Data61/2D3D data over the aforementioned datasets is that the panoramic images provide an opportunity to capture each object several times in different frames and from different viewpoints. Therefore it not only provides the corresponding 2D information for each 3D segment, but also does it several times from different views.

Figure 1. Example of 3D data, 2D data, 3D labeler and 2D labeler
Download Data61/2D3D Dataset
Download the Data61/2D3D Dataset. (Please note that some file sizes are quite large and may take time to download).
For further information on the Pedestrian Dataset, please contact Lars.Petersson@data61.csiro.au
Data61 Pedestrian Dataset
The Data61 Pedestrian Dataset is made freely available to the scientific community. Any publications resulting from the use of this dataset, and derivative forms, should cite the following paper:
G. Overett, L. Petersson, N. Brewer, L. Andersson and N. Pettersson, A New Pedestrian Dataset for Supervised Learning, In IEEE Intelligent Vehicles Symposium, 2008.
The final dataset contains 25551 unique pedestrians, allowing for a dataset of over 50K images with mirroring. Additionally, TDB allows the generation of several permutations per source image in order to further bolster the training set. Large negative datasets will also be provided, although researchers training cascaded classifiers may require their own bootstrapped negative datasets. Apart from the datasets linked here the authors are willing, within reason, to produce further pedestrian datasets for the scientific community.
Figure 1. shows a selection of pedestrians from the dataset. Most images were captured using normal digital camera hardware in normal urban environments, in multiple cities and in different countries.
The negative set is drawn from a set of 5207 high resolution pedestrian free images in varied environments. Both the negative and positive sets are divided into unique folds for tasks such as validation.

Figure 1. Example 32×80 Pedestrians
Download Pedestrian Dataset
Download the Pedestrian Dataset. (Please note that some file sizes are quite large and may take time to download).
For further information on the Pedestrian Dataset, please contact Lars.Petersson@data61.csiro.au
This dataset (‘Licensed Material’) is made available to the scientific community for non-commercial research purposes such as academic research, teaching, scientific publications or personal experimentation. Permission is granted by National ICT Australia Limited (Data61) to you (the ‘Licensee’) to use, copy and distribute the Licensed Material in accordance with the following terms and conditions:
- Licensee must include a reference to Data61 and the following publication in any published work that makes use of the Licensed Material: G. Overett, L. Petersson, N. Brewer, L. Andersson and N. Pettersson, A New Pedestrian Dataset for Supervised Learning, In IEEE Intelligent Vehicles Symposium, 2008.
- If Licensee alters the content of the Licensed Material or creates any derivative work, Licensee must include in the altered Licensed Material or derivative work prominent notices to ensure that any recipients know that they are not receiving the original Licensed Material.
- Licensee may not use or distribute the Licensed Material or any derivative work for commercial purposes including but not limited to, licensing or selling the Licensed Material or using the Licensed Material for commercial gain.
- The Licensed Material is provided ‘AS IS’, without any express or implied warranties. Data61 does not accept any responsibility for errors or omissions in the Licensed Material.
- This original license notice must be retained in all copies or derivatives of the Licensed Material.
- All rights not expressly granted to the Licensee are reserved by Data61.
Globally-Optimal Pose And Correspondences (GOPAC) Code
The code for Globally-Optimal Pose And Correspondences (GOPAC) is made freely available to the scientific community. Any publications resulting from the use of this code should cite the following papers:
- Dylan Campbell, Lars Petersson, Laurent Kneip and Hongdong Li, “Globally-Optimal Inlier Set Maximisation for Camera Pose and Correspondence Estimation”, IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), IEEE, June 2018
- Dylan Campbell, Lars Petersson, Laurent Kneip and Hongdong Li, “Globally-Optimal Inlier Set Maximisation for Simultaneous Camera Pose and Feature Correspondence”, Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, IEEE, October 2017, pp. 1-10
Abstract:
Estimating the 6 DoF pose of a camera from a single image relative to a pre-computed 3D point-set is an important task for many computer vision applications. Perspective-n-Point (PnP) solvers are routinely used for camera pose estimation, provided that a good quality set of 2D-3D feature correspondences are known beforehand. However, finding optimal correspondences between 2D key-points and a 3D point-set is non-trivial, especially when only geometric (position) information is known. Existing approaches to the simultaneous pose and correspondence problem use local optimisation, and are therefore unlikely to find the optimal solution without a good pose initialisation, or introduce restrictive assumptions. Since a large proportion of outliers are common for this problem, we instead propose a globally-optimal inlier set cardinality maximisation approach which jointly estimates optimal camera pose and optimal correspondences. Our approach employs branch-and-bound to search the 6D space of camera poses, guaranteeing global optimality without requiring a pose prior. The geometry of SE(3) is used to find novel upper and lower bounds for the number of inliers and local optimisation is integrated to accelerate convergence. The evaluation empirically supports the optimality proof and shows that the method performs much more robustly than existing approaches, including on a large-scale outdoor data-set.
Download the TPAMI paper and the appendix. Download the ICCV paper and the appendix.
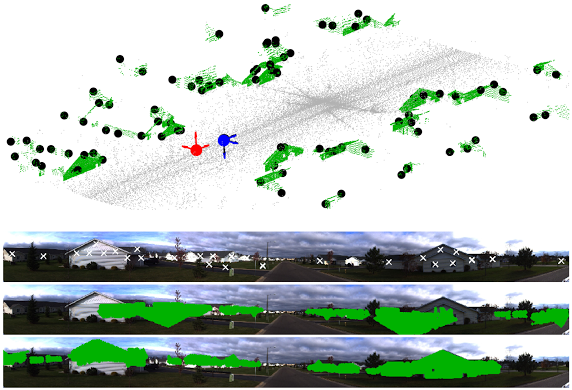
Estimating the pose of a calibrated camera from a single image within a large-scale, unorganised 3D point-set captured by vehicle-mounted laser scanner. Our method solves the absolute pose problem while simultaneously finding feature correspondences, using a globally-optimal branch-and-bound approach with tight novel bounds on the cardinality of the inlier set: (top) 3D point-set (grey and green), 3D features (black dots) and ground-truth (black), RANSAC (red) and our (blue) camera poses; (upper middle) panoramic photograph and extracted 2D features; (lower middle) building points projected onto the image using the RANSAC camera pose; (bottom) building points projected using our camera pose.
Download Globally-Optimal Pose and Correspondences Code
Download the code for Globally-Optimal Pose And Correspondences. The gopac zip file contains a README.txt file in the root folder. The license can be viewed in the license.txt file in the root directory. For further information on the code, please contact dylan.campbell@data61.csiro.au or lars.petersson@data61.csiro.au.
Globally-Optimal Gaussian Mixture Alignment (GOGMA) Code
The code for Globally-Optimal Gaussian Mixture Alignment (GOGMA) is made freely available to the scientific community. Any publications resulting from the use of this code should cite the following papers:
- Dylan Campbell and Lars Petersson, “GOGMA: Globally-Optimal Gaussian Mixture Alignment”, Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, IEEE, Jun. 2016.
- Dylan Campbell and Lars Petersson, “An Adaptive Data Representation for Robust Point-Set Registration and Merging”, Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, IEEE, Dec. 2015, pp. 4292-4300.
Abstract:
Gaussian mixture alignment is a family of approaches that are frequently used for robustly solving the point-set registration problem. However, since they use local optimisation, they are susceptible to local minima and can only guarantee local optimality. Consequently, their accuracy is strongly dependent on the quality of the initialisation. This paper presents the first globally-optimal solution to the 3D rigid Gaussian mixture alignment problem under the L2 distance between mixtures. The algorithm, named GOGMA, employs a branch-and-bound approach to search the space of 3D rigid motions SE(3), guaranteeing global optimality regardless of the initialisation. The geometry of SE(3) was used to find novel upper and lower bounds for the objective function and local optimisation was integrated into the scheme to accelerate convergence without voiding the optimality guarantee. The evaluation empirically supported the optimality proof and showed that the method performed much more robustly on two challenging datasets than an existing globally-optimal registration solution.
Download the paper and the appendix.
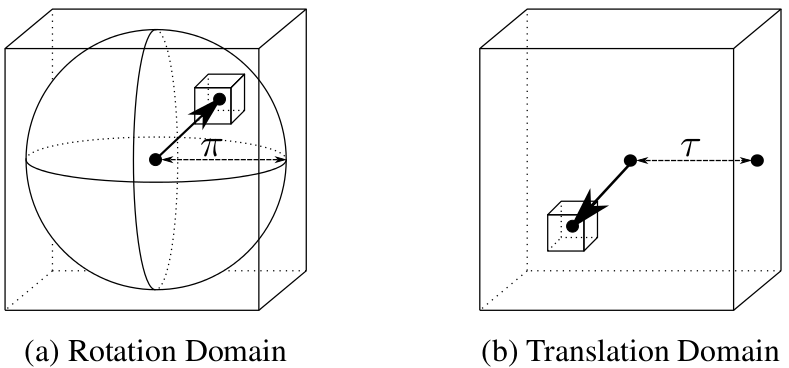
Figure 1. Parametrisation of SE(3). (a) The rotation space SO(3) is parametrised by angle-axis 3-vectors within a solid radius-pi ball. (b) The translation space R3 is parametrised by 3-vectors within a cube of half side-length tau. The joint domain is branched using a hyperoctree data structure, with a sub-hypercube depicted as two sub-cubes Cr and Ct in the rotation and translation dimensions.
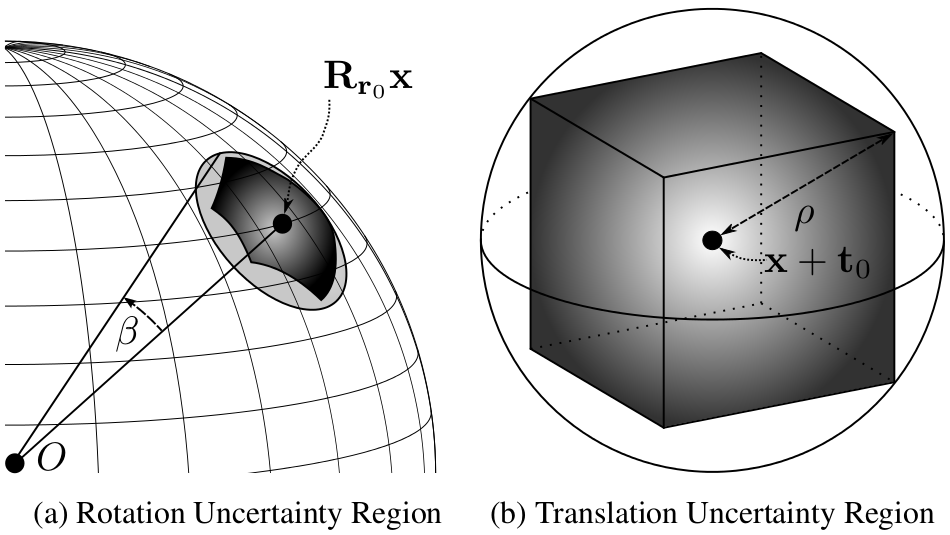
Figure 2. Uncertainty region induced by hypercube C = Cr x Ct. (a) Rotation uncertainty region for Cr with centre Rr0x. The optimal rotation of x may be anywhere within the heavily-shaded umbrella-shaped uncertainty region, which is entirely contained by the lightly-shaded spherical cap defined by Rr0x and beta. (b) Translation uncertainty region for Ct with centre x + t0. The optimal translation of x may be anywhere within the cube, which is entirely contained by the circumscribed sphere with radius rho.
Download Globally-Optimal Gaussian Mixture Alignment Code
Download the code for Globally-Optimal Gaussian Mixture Alignment. C++ and CUDA code is included. The gogma zip file contains a README.txt file in the root folder. The license can be viewed in the license.txt file in the root directory. For further information on the code, please contact dylan.campbell@data61.csiro.au or lars.petersson@data61.csiro.au.
Support Vector Registration (SVR) Code
The code for Support Vector Registration (SVR) is made freely available to the scientific community. Any publications resulting from the use of this code should cite the following paper:
- Dylan Campbell and Lars Petersson, “An Adaptive Data Representations for Robust Point-Set Registration and Merging”, Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, IEEE, Dec. 2015
Abstract:
This paper presents a framework for rigid point-set registration and merging using a robust continuous data representation. Our point-set representation is constructed by training a one-class support vector machine with a Gaussian radial basis function kernel and subsequently approximating the output function with a Gaussian mixture model. We leverage the representation’s sparse parametrisation and robustness to noise, outliers and occlusions in an efficient registration algorithm that minimises the L2 distance between our support vector–parametrised Gaussian mixtures. In contrast, existing techniques, such as Iterative Closest Point and Gaussian mixture approaches, manifest a narrower region of convergence and are less robust to occlusions and missing data, as demonstrated in the evaluation on a range of 2D and 3D datasets. Finally, we present a novel algorithm, GMMerge, that parsimoniously and equitably merges aligned mixture models, allowing the framework to be used for reconstruction and mapping.
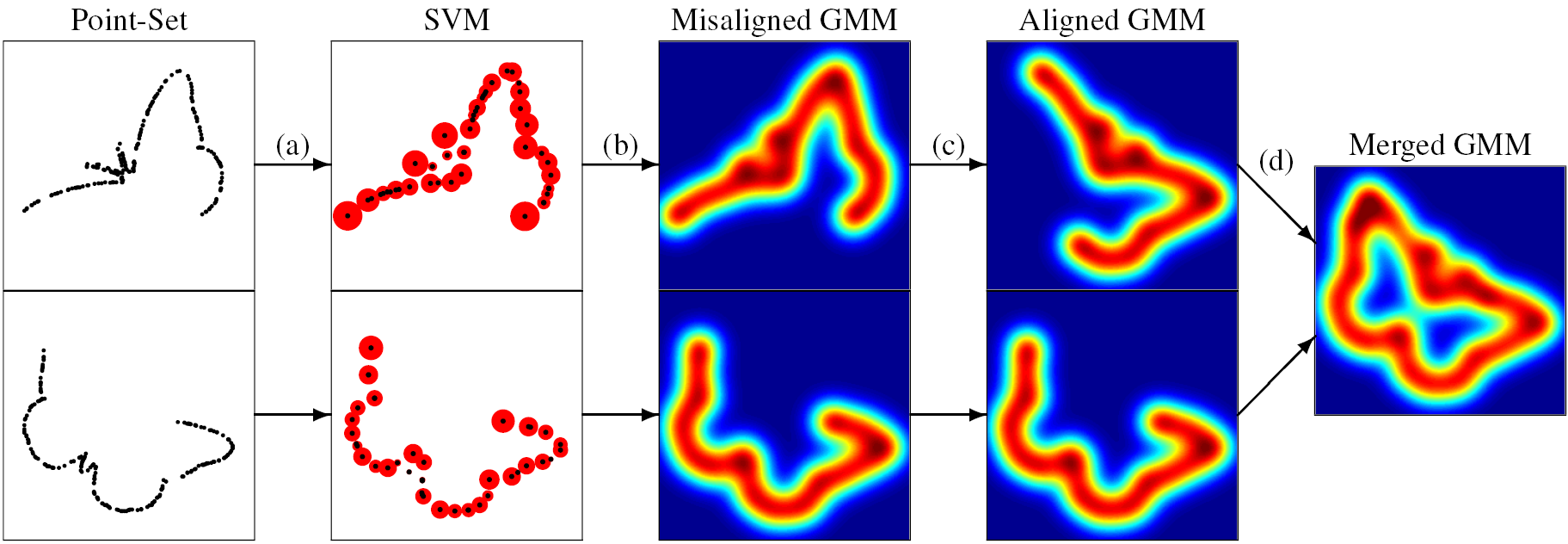
Figure 2. Robust point-set registration and merging framework. An nD point-set is represented as an SVGM by training a one-class SVM (a) and then mapping it to a GMM (b). The SVR algorithm is used to minimise the L2 distance between two SVGMs in order to align the densities (c). Finally, the GMMerge algorithm is used to parsimoniously fuse the two mixtures. The SVMs are visualised as support vector points scaled by mixture weight and the SVGMs are coloured by probability value.
Download Support Vector Registration Code
Download the code for Support Vector Registration. MATLAB and C++ versions of the code are included. The C++ version is significantly faster, but the MATLAB optimisation package is more powerful and so tends to be more stable and accurate. The svr.zip file contains README files in the distribution/MATLAB/demo and distribution/C++/build folders. The license can be viewed in the license.txt file in the root directory. For further information on the code, please contact dylan.campbell@data61.csiro.au or lars.petersson@data61.csiro.au.