Object & Scene Segmentation
This project aims to segment objects and infer scene layout from images and videos. We have designed a state-of-the-art examplar-based approach to jointly segment object and scene in video from semantic and geometric perspective.
For deeper scene understanding, it is critical to simultaneously segment multiple objects and/or infer geometric layout of the scene from an image or video. The challenges are due to large variations in object appearance and shape, occlusion between objects and complex nature of object-scene relations. Current approaches do not work well with multiple interacting objects, lack rich scene representation, and rely on extensive training with many annotated images.
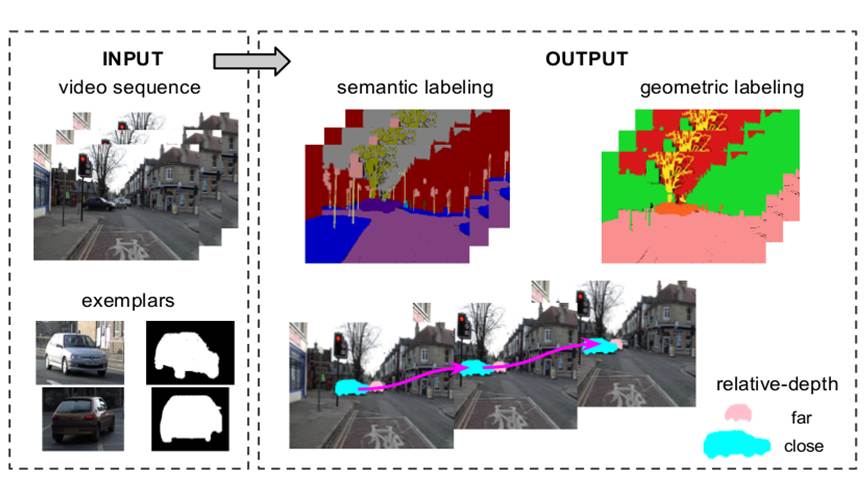
We make use of a small number of object examples annotated with shape masks and jointly segment all the object instances and/or regions in an image/video. Our approach is capable of exploiting object shape prior and encoding the geometric relation between objects (e.g., occlusion), which yields a richer scene representation, efficient learning method and better segmentation performance. We integrate geometric and semantic cues and propose a novel conditional random field framework.
We have achieved the state-of-the-art performance on several public video parsing benchmarks. We plan to extend our method to wider range of object classes and richer representation of dynamic scenes.
Potential applications
- Automatic driving
- Assistive robot
- Video analytics
- Remote sensing and medical image analysis
