Provenance
Provenance Management
Overview
Provenance refers to the chain of successive custody—including sources and operations of resources such as hardware, software, documents, databases, data, and other entities. It is also concerned with the original sources of any subsequent changes or other treatment of information and resources throughout the life cycle of data. That information may be in any form, including software, text, spreadsheets, images, audio, video, proprietary document formats, databases, and others, as well as meta-level information about information.
Individuals and organizations routinely work with, and make decisions based on, data that may have originated from many different sources and also may have been processed, transformed, interpreted, and aggregated by numerous entities between the original sources and the consumers. Without good knowledge about the sources and its provenance, it can be difficult to assess the data’s trustworthiness and reliability, and hence its real value to the decision-making processes in which it is used.
Challenges
Numerous gaps in provenance and tracking research remain to be filled, requiring a much broader view of the problem space and cross-disciplinary efforts to capture unifying themes and advance the state of the art for the benefit of all communities interested in provenance. Provenance research is not a standalone topic. It synthesizes multiple research areas such as traditional data management, semantic knowledge management, graph theorem, network analysis etc. to address many challenges such as granularity, integrity, confidentiality, trustworthiness, heterogeneity, efficiency, usability etc.
Research Capabilities
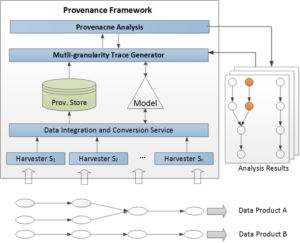
The team has this unique capability to work on provenance modelling and provenance analysis by taking the advantages of past data management and analysis experience. By incorporating domain knowledge into provenance modeling as well as analysis process, we also enrich provenance with semantics to generate knowledge provenance. It greatly helps users make informed decisions on their fitness for use. We have been working on the following main perspectives of provenance research:
- Representation: data models and structures for provenance
- Management: creation and revocation of indelible distributed provenance
- Presentation: queries, displays, analysis
- System engineering: Integration into trustworthy systems
Contact: Qing Liu, Q.Liu<at>csiro.au; Yanfeng Shu, Yanfeng.Shu<at>csiro.au
Selected Publications
- Semantic Similarity of Workflow Traces with Various Granularities, Q. Liu, Q. Bai, Y. Yang, The International Conference on Web Information Systems Engineering (WISE), 2016
- A Partition-Based Approach to Structure Similarity Search, X. Zhao, C. Xiao, X. Lin, Q. Liu, W. Zhang, The Proceedings of VLDB Endowment (PVLDB), 2014
- Towards Semantic Comparison of Multi-Granularity Process Traces, Q. Liu, X. Zhao, K. Taylor, X. Lin, S. Geoffrey, K. Corne and M. Richard, Journal of Knowledge-based Systems, Elsevier, 2013
- CTrace: Semantic Comparison of Multi-granularity Process Traces, Q. Liu, K.Taylor, X.Zhao, G.Squire, X.Lin, and C.Kloppers, The Annual ACM International Conference on Management of Data (SIGMOD), 2013
- Case-based Trust Evealuation from Provenance Information, Bai, X.Su, Q.Liu, A.Terhorst, M.Zhang, Y.Mu, IEEE International Conference on Trust, Security and Privacy in Computing and Communications (IEEE TrustCom), 2011