Data Privacy as Business Opportunity
Organisations and companies are increasingly collecting and using their customers’ personal data for their business purposes. However, the need to keep the customer data private and conform to privacy regulations raises a host of limitations.
However data privacy can be seen not as a hindrance, but as a catalyst for new business opportunities. Privacy as a business differentiator can potentially increase customer trust and their willingness to share more data and use the services provided by the business. Quantifying the risk customers may be taking when releasing some data to the businesses is of a paramount importance. Second, collected data is naturally of high value to third parties, who might be interested in specific attributes.
The challenge is to apply data privacy preservation mechanisms, which will allow businesses to share insights from the data they collected, while conforming to existing regulations and not compromising their customers’ privacy.
At present our research is in two directions
Privacy-Utility Tradeoff in Publishing Data about Supermarket Transactions
The key question answered in this research is the exact level of tradeoff between privacy and utility that gives the most benefit to the third parties while satisfies the privacy requirements of the customers. For this, we use various algorithms of syntactic anonymity and then analyze the data for its perceived and potential utility.
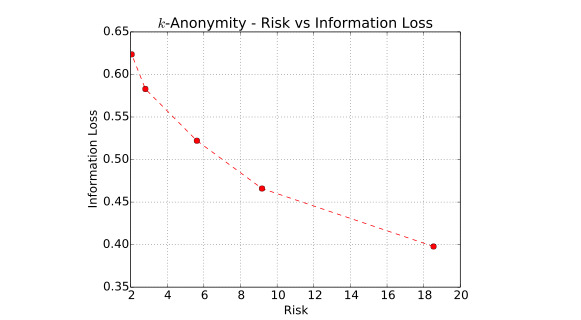
Re-identification
What is the risk of re-identification if and when customer data is released provided some relevant data about the same customers is publicly available? We investigate techniques and algorithms that can de-anonymize users across different databases. Some of these techniques are specific to the characteristics of data, whereas others are generic and can be applied to a host of different datasets.
Recent Publications
- Hassan Jameel Asghar, Shlomo Berkovsky & Mohamed Ali Kaafar 2016, Syntactic Anonymity for Privacy Preservation of Reward Programs Customers, Technical Report.