Data Analytics Platform
Strategy
For an increasing number of usage scenarios, data analytics and machine learning demonstrate effectiveness in handling real-world tasks with little human involvement. The demand for constructing such kinds of systems rises rapidly but the actual construction of such a system requires lots of effort. It is not only because such systems are often data and compute intensive, which is a challenge for decision making in a timely manner, but also because there are always unexpected situations in real-world applications and evaluating data analytics outcomes or machine learning models learned from known data under new situations as well as under various policy frameworks is non-trivial. Our research intends to meet these demands by studying solutions of the following problems:
- How to improve the development/usage practice for data analytics and machine learning systems in order to enhance certainty of these systems and address legal, compliance and ethical issues involved in their real-world use?
- How to improve current distributed, parallel systems and data management techniques to meet the data analytics needs for real-time and high quality decision making based on heterogeneous data, particularly for important application areas such as scientific computing and health informatics?
- The complex mixing of data and computation erodes the abstraction boundaries in traditional software engineering practices, which challenges the applicability of traditional principles in ensuring software quality. How to ensure the quality of a software system that integrates data analytics or machine learning subsystems? Moreover, how to ensure the quality of a software system that is partially generated from machine learning algorithms?
We investigate processes of machine learning models construction through reviewing existing practices and building concrete data analytics applications. We develop software systems to make these processes efficient and manageable, and validate our solutions by applying them to concrete applications in our target areas to measure effectiveness.
Our team has solid skills and track records on software engineering, distributed systems and parallel computing research, which are fundamental to this topic.
Relevant Projects
- Data integration: we develop Spark based fast and accurate data duplicate detection system, causality driven data integration system for drug side effect discovery, and exploit data similarity for storage compressibility / deduplication to accommodate rapidly growing “similar” data efficiently.
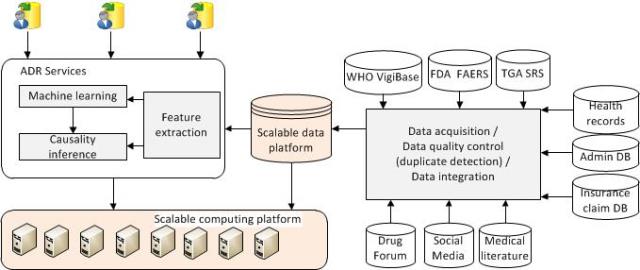
Integrating data for drug side effect discovery
- “Big data” handling: We develop large scale distributed systems to handle radio telescope data processing and apply deep learning techniques to automate data processing to remove bottlenecks using Tensorflow in large GPU clusters. We collaborate with the Five-hundred-meter Aperture Spherical radio Telescope (FAST) team in Chinese Academy of Science on developing data sharing, archiving, provenance data collection, multiple time series data analytics and Pulsar search result ranking methods. We also develop efficient methods for managing shared cloud resource for dealing with both data- and compute-intensive computing.

The Five hundred meter Aperture Spherical Telescope (FAST)
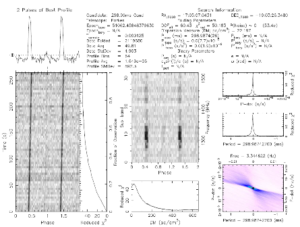
Pulsar Signals
- Hierarchically Distributed Data Matrix (HDM): A distributed execution engine that provides a functional meta-data abstraction for Big Data processing. It provids built-in planner and optimizer to simplify the functional computation graph (10 to 60% faster for different types of operations compared with Spark 1.6.2). It supports multi-cluster architecture and dependency and execution history management.
Publications:
- A Case Based Deep Neural Network Interpretability Framework and Its User Study
R Nadeem, H Wu, H Paik, C Wang
International Conference on Web Information Systems Engineering, 147-161 - Towards Effective Data Augmentations via Unbiased GAN Utilization
S Verma, C Wang, L Zhu, W Liu
Pacific Rim International Conference on Artificial Intelligence, 555-567 - A compliance checking framework for DNN models
S Verma, C Wang, L Zhu, W Liu
Proceedings of the 28th International Joint Conference on Artificial … - H. Wu, C. Wang, J. Yin, K. Lu, L. Zhu, Sharing Deep Neural Network Models with Interpretation, Proc. 27th International World Wide Web Conference (WWW), 2018.
- H. Wu, C. Wang, Y. Fu, S. Sakr, K. Lu, L. Zhu, A Differentiated Caching Mechanism to Enable Primary Storage Deduplication in Clouds, IEEE Transactions on Parallel and Distributed Systems (TPDS), 2018 (in press).
- H. Wu, C. Wang, Y. Fu, S. Sakr, L. Zhu, K. Lu, HPDedup: A Hybrid Prioritized Data Deduplication Mechanism for Primary Storage in the Cloud, 33rd International Conference on Massive Storage Systems and Technology (MSST) 2017.
- X. Zhou, L. Chen, Y. Zhang, D. Qin, L. Cao, G. Huang, C. Wang, Enhancing online video recommendation using social user interactions,The VLDB Journal 26 (5), 637-656, 2017.
- D. Wu, S. Sakr, L. Zhu, H. Wu, Towards Big Data Analytics across Multiple Clusters. Proc. 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGrid), 2017.
- D. Wu, L. Zhu, Q. Lu, S. Sakr, HDM: A Composable Framework for Big Data Processing, IEEE Transactions on Big Data , 2017 (in press).
- C. Wang, S. Karimi, Parallel Duplicate Detection in Adverse Drug Reaction Databases with Spark, Proc. 19th International Conference on Extending Database Technology (EDBT), 2016.
- S. Karimi, C. Wang, A. Metke-Jimenez, R. Gaire, C. Paris, Text and data mining techniques in adverse drug reaction detection, ACM Computing Surveys (CSUR) 47(4), 2015.
- K. Ye, Z. Wu, C. Wang, B. B. Zhou, W. Si, X. Jiang, A. Y. Zomaya, “Profiling-Based Workload Consolidation and Migration in Virtualized Data Centers,” IEEE Transactions on Parallel and Distributed Systems (TPDS), vol. 26, no. 3, pp. 878-890, March 2015.
- C. Wang, S. Karimi, Causality driven data integration for adverse drug reaction discovery, Health Informatics Society Australia (HISA) Big Data Conference, 2014.
- X. Liu, C. Wang, B. B. Zhou, J. Chen, T. Yang and A. Y. Zomaya, Priority-Based Consolidation of Parallel Workloads in the Cloud, IEEE Transactions on Parallel and Distributed Systems(TPDS), vol. 24, no. 9, pp. 1874-1883, Sept. 2013.
- J. Chen, C. Wang, B. B. Zhou, L. Sun, Y. C. Lee, and A. Y. Zomaya. 2011. Tradeoffs between Profit and Customer Satisfaction for Service Provisioning in the Cloud. Proc. 20th international symposium on High performance distributed computing (HPDC ’11). ACM, New York, NY, USA, 229-238.
- C. Wang, Y. Zhou, A Collaborative Monitoring Mechanism for Making a Multitenant Platform Accountable. USENIX HotCloud 2010.
Contact:
Chen Wang (chen.wang@data61.csiro.au)
Architecture & Analytics Platforms, Data61, CSIRO